My PDF Journey: Conversations with ChatGPT and a $7 Debt Lesson

Over the past few days, I have been exploring the idea of allowing ChatGPT to read my PDF documents and answer a few questions from them. Taking inspiration from the numerous ChatWithPDF software available, I decided to embark on a journey of building a small script in Google Colab, simply for the sake of the experience. In less than a few minutes, I discovered how expensive this approach can be, as the tokens used to converse with these documents kept increasing, meaning I was accumulating more debt each time I ran the script.
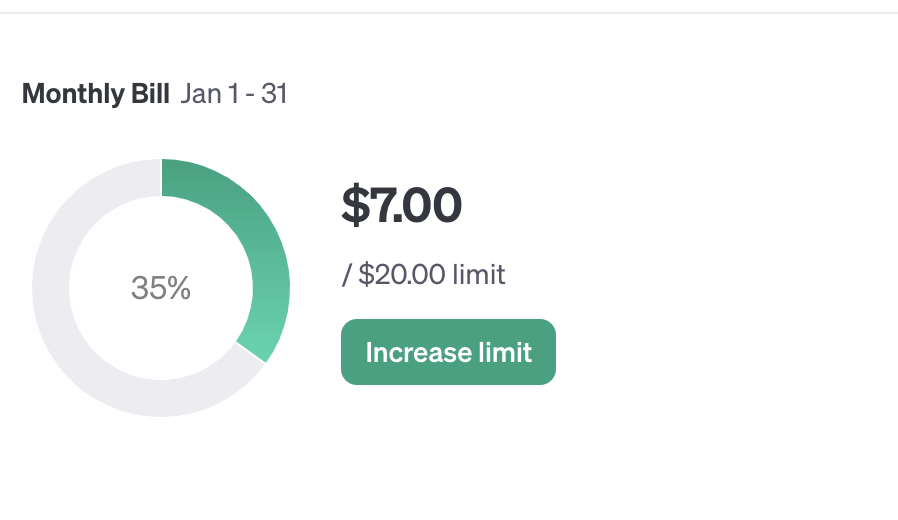
Below is a screenshot of the expenses I incurred after chatting with several PDFs. Spending so much on conversing with my PDFs 😮, I could have just read them myself 😔.
For this experiment, I employed a simple pre-processing technique in NLP, removing stopwords from the corpus of each PDF to reduce the length of the prompts I would be passing to GPT. Of course, this is not the only option for this kind of task; I chose it as a mini-project to reflect on my newly acquired NLP power 💪 The image below displays the sum of all the tokens used, the original length of the PDFs, and the final length after the removal of stopwords.
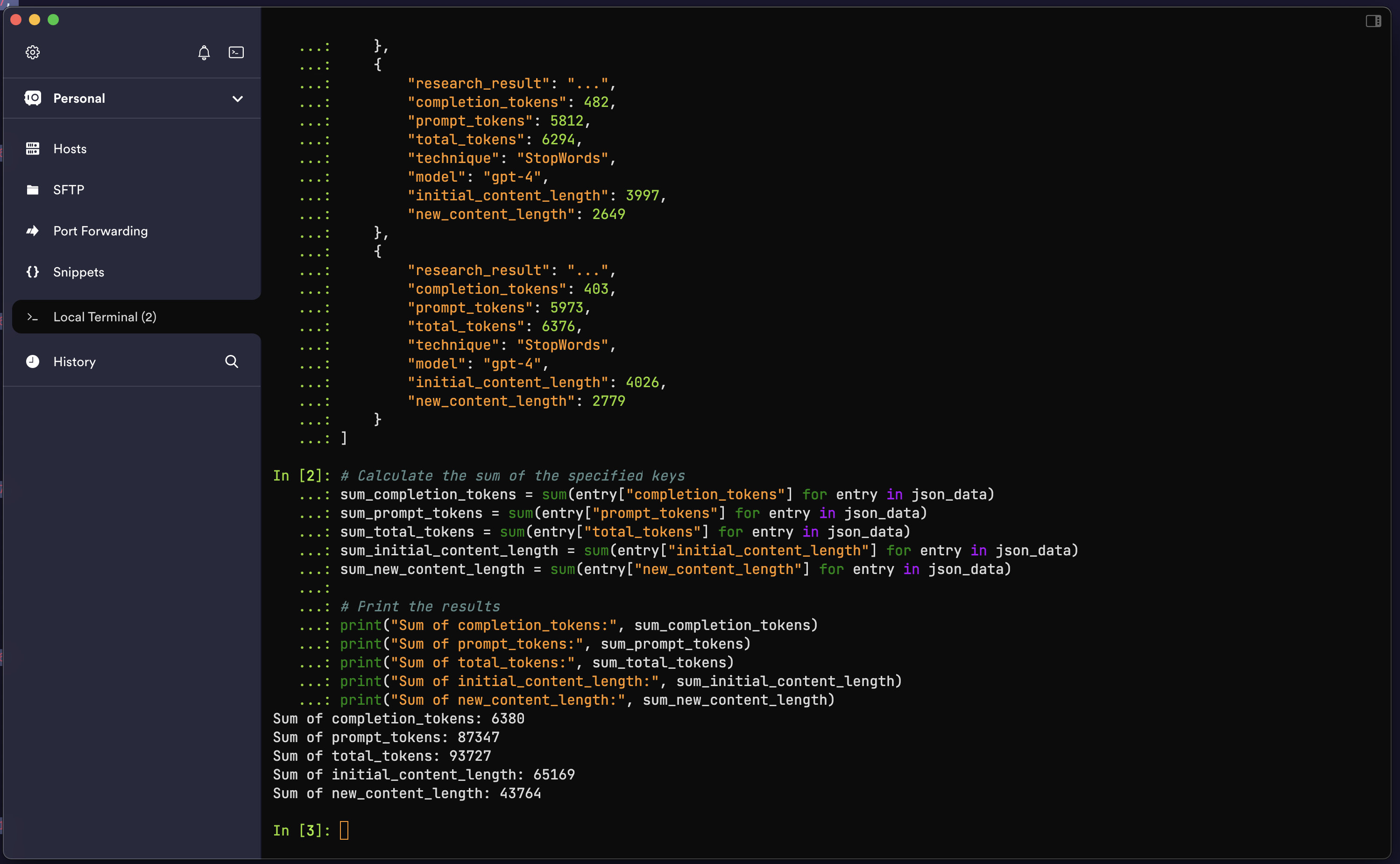
I also need to mention that I could only pass 5-8 pages at most for each PDF, as the context window limit applies to some PDFs for documents with lengthy pages. In essence, I could only chat with a few of the documents I have.
With these results and my $7 debt, I conclude that using existing ChatWithPDF sites can be helpful, as I don't want to keep accumulating so much debt. Simultaneously, taking a closer look at this problem and my newfound superpower in NLP (due to a growing interest in machine learning, hence the reason for the mini-project), I challenge myself to figure out all the available and suitable techniques in NLP (RAG 😜 ?) I could employ it to reduce the cost of chatting with my PDFs.
In this series of blogs, I will be sharing my progress, and what I am learning, and hopefully, I won't incur much debt.