What I learnt while building QACLI
After my recent debt of $7 incurred using the OpenAI API, I decided to embark on figuring out how to reduce my cost. I ended up building my RAG-powered system which is running offline, QACLI. QACLI is a proof-of-concept for another project. As a software engineer, I decided to document a few bits I am learning or would like to re-emphasise. This blog article is then a sort of piece to be used for my revision from time to time. By the way, QACLI is an acronym for Question and Answering Command Line Interface.
The first lesson here is the importance of reading documentation. I decided to pick the Lang Chain framework to power the RAG part of the system. I was able to build such a system without having to rely on half-baked tutorials that usually fill the internet. Seriously, such tutorials are not bad since they help me get started easily, I normally take it upon myself to understand what the authors of the framework or library I am using are thinking and why they decided to implement it in the way they did. The outcome of reading the Langchain-provided documentation is an in-depth understanding of what Langchain can do and a better decision when implementing features.
QACLI is an interesting project for me, this allows me to think of possible ways of enhancing the project to the best possibility I can. I decided to use concurrency (I miss Java concurrency 🥹). Reading the Python documentation helped me to (re)understand concurrent.futures better. After reading this, I understand what ChatGPT is talking about (🤷🏿♂️ well, who doesn't rely on such assistance these days?) and can validate its suggestion. Why do I have to dig into the documentation? this piece of code below would likely take time and I want them to happen quickly and concurrently.
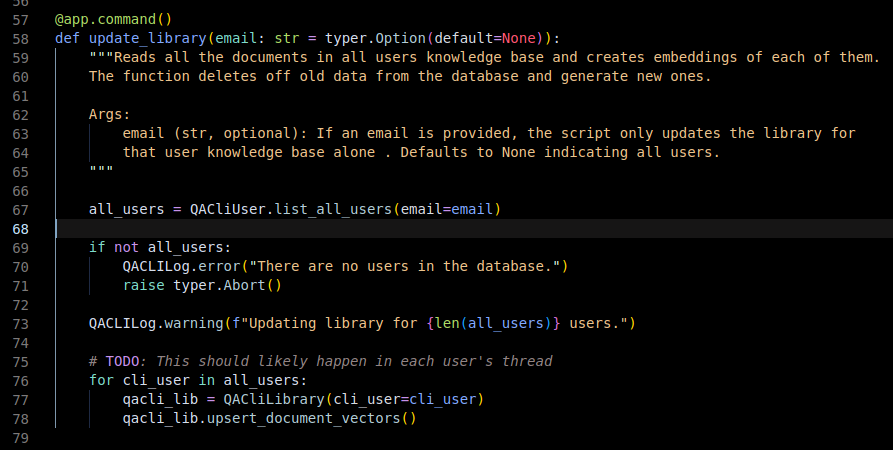
A simple refactor in the function above is to change the variable name from
all_userstousers. The reason is because thelist_all_usersfunction is not really returning all users if the email is provided. A second refactor is to change the function name tolist_usersor to change the name entirely, you know why already 😉
Random stuff I ask ChatGPT 🫤. (Did you see that mistake in the prompt at the end? Yet, GPT can figure things out, isn't that concerning? 🫠)

For the database that powers both regular data and is used as a vector store, I used PostgreSQL (and pgvector extension) via the supabase. I read the superbase documentation too, though I have to take a clue from its JS version of docs to better understand the community Python library.
A big takeaway is that, I should continually improve my written documentation to help and assist other developers when they are looking at my codebase or trying to use some functions I wrote.
The last three lessons are my favourite because they show how important different pieces of a system contribute to the overall success of such a system.
The above discusses how I am loading the documents. For my use case, I found out that loading the PDF manually works best for me. Now this is not to say the default loader is faulty, I am just experimenting and I found a better result.

The two retriever techniques that stood out for my use case are Long Content Re-order and Contextual Compression. I found out that these two techniques work well for long texts. My documents have a lot of pages, this could be too much for the model to figure out an answer. After experimenting with two retriever techniques, and tweaking my base prompt, I found a better response.
And lastly, at some point, my machine was making some noise 😒. I found out it is because the model is probably trying to figure out the golden answer to my question over a high number of relevant documents. Reducing the number of retrieved relevant documents (from 20 🫣 to 5 or less) calmed the machine. The takeaway here is that the more the number of relevant documents the more the memory usage.
It took me less than a week to implement this application, quite impressive to me because most of the technologies such as Lang Chain and supabase, I haven't used them in previous projects. I did this while still combining these with other time-demanding commitments. 💪🏿
And finally gentlemen and ladies, I was able to reduce my cost, build a custom RAG-powered system (ChatGPT if you will) and learn a couple of topics. In this blog, I did not go deep into what LLM I used and other too technical details of the system, the reason being that I am still doing more research on these across multiple use cases, a deeper dive-in will deserve its blog, stay tuned.
Thanks for reading.